

In an increasingly digital world, where audio and voice data are growing at an incredible pace, speech-to-text (STT) models are proving to be essential tools for converting spoken language into written text with accuracy and speed.
STT technology unlocks remarkable possibilities in diverse fields, from hands-free digital assistance and real-time meeting transcription to accessibility for individuals with hearing impairments and even automated customer support. This blog will dive into the fascinating world of STT models
Open Source Models
Whisper ASR
- Whisper is an open-source, multilingual STT model created by OpenAI. It is a Transformer based encoder-decoder model.
- It supports 99 languages. They show strong ASR results in ~10 languages.
- Known for its high accuracy and robustness across accents and noisy environments.
- Whisper is widely used for both simple and complex transcription tasks, including multilingual transcription and translation.
- Whisper is available in different sizes - tiny, base, small, medium, large, large-v2, large-v3, large-v3-turbo.
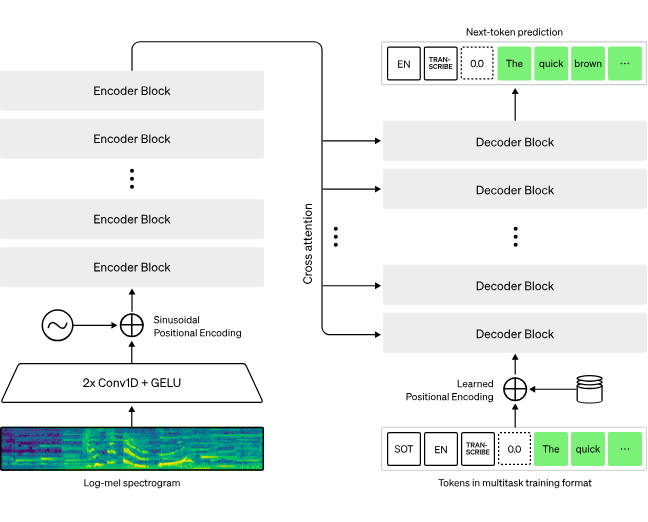
NVIDIA Nemo Canary
- The NVIDIA NeMo Canary-1B is an advanced, multilingual model for speech-to-text and speech translation tasks, powered by 1 billion parameters.
- It provides highly accurate transcription for English, German, French, and Spanish and can translate between these languages with optional punctuation and capitalization.
- Built on a FastConformer encoder and Transformer decoder, Canary-1B efficiently extracts audio features and generates text through task-specific tokens, making it adaptable to various applications.
- The model was trained on an extensive dataset of 85,000 hours, encompassing public and proprietary speech data, ensuring robustness across diverse contexts.
- Users can leverage the NeMo toolkit to easily integrate this pre-trained model, either for direct transcription or for further fine-tuning on custom datasets.
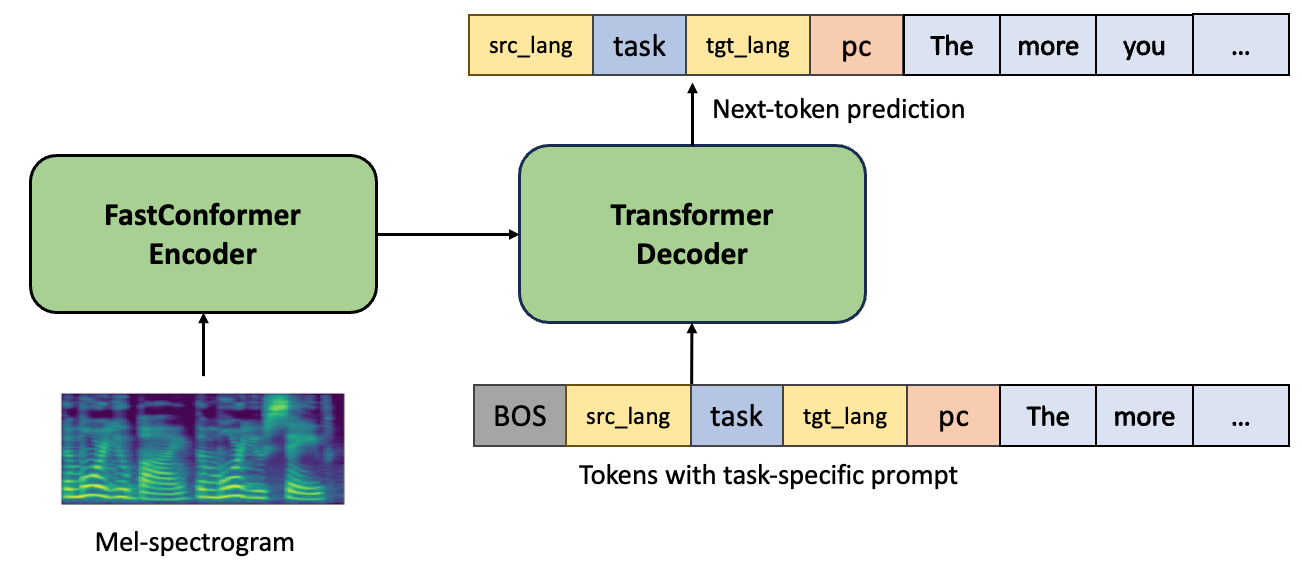
Revai
- Rev’s Reverb ASR model is a groundbreaking English ASR system trained on an enormous dataset of 200,000 hours of high-quality, human-transcribed audio, making it one of the most accurate open-source ASR models available.
- Its flexible architecture can run on both CPU and GPU, offering broad accessibility and performance across different setups.
- Reverb ASR allows users to control transcription detail through a unique "verbatimicity" setting, which adjusts how closely the transcript follows the original spoken content, from fully verbatim (capturing every hesitation and filler) to non-verbatim for clean, readable output.
- The model uses a sophisticated joint CTC/attention architecture, supporting multiple decoding modes like attention, CTC greedy search, and attention rescoring, ensuring robust performance across various transcription needs.
- With this combination of accuracy, flexibility, and user control, Reverb ASR is ideal for applications from audio editing to professional transcription.
Partner with Us for Success
Experience seamless collaboration and exceptional results.
Closed Source Models
Deepgram
- Deepgram is an advanced automatic speech recognition (ASR) platform known for its high-speed processing and customizability, designed to handle large volumes of audio data efficiently.
- Built with deep learning models, it supports real-time transcription and offers 36+ language support, catering to diverse global use cases.
- Deepgram allows users to fine-tune models for specific industries, such as call centers, healthcare, and media, enhancing accuracy for unique vocabularies and acoustic environments.
- The platform also includes features like diarization, which can distinguish between different speakers, and keyword boosting to prioritize certain words.
- With options for both cloud and on-premise deployment, Deepgram is highly versatile for businesses with varied data security and compliance needs.
Assembly AI
- Assembly AI is a powerful speech-to-text API that leverages deep learning to provide highly accurate transcriptions with advanced capabilities.
- It offers various add-on features such as topic detection, sentiment analysis, and speaker diarization, which enrich the transcription experience by providing valuable insights alongside raw text.
- Known for its simplicity and ease of integration, Assembly AI enables developers to quickly incorporate ASR functionality into their applications with minimal setup.
- Its API supports both real-time and pre-recorded audio processing, making it versatile for applications ranging from live captioning to large-scale media transcription.
- Additionally, Assembly AI maintains robust data privacy standards, which is essential for businesses in regulated industries such as healthcare and finance.
Sarvam AI
- Sarvam AI is an innovative speech-to-text solution tailored to support multiple languages and dialects, making it suitable for diverse linguistic environments.
- Known for its high accuracy in recognizing regional accents and variations, Sarvam AI addresses transcription challenges often overlooked by more generic ASR systems.
- It offers features like noise cancellation and automatic punctuation, improving clarity and readability even in noisy or complex audio settings.
- Designed with scalability in mind, Sarvam AI can process both real-time and batch audio, making it ideal for businesses with high transcription demands.
- Additionally, Sarvam AI prioritizes user data privacy, ensuring secure handling of sensitive audio content for industries with strict compliance requirements.
Partner with Us for Success
Experience seamless collaboration and exceptional results.
Comparison of Speech-to-Text Models
Conclusion
Speech-to-text technology has become increasingly sophisticated, offering solutions for every need. Whether you opt for open-source models like Whisper or closed-source solutions like Deepgram, each brings unique advantages. Consider your specific requirements for language support, accuracy, and deployment options when choosing the right STT model for your project.
Frequently Asked Questions?
1. What's the difference between open-source and closed-source speech-to-text models?
Open-source models like Whisper are freely accessible and modifiable, while closed-source solutions like Deepgram offer proprietary features with commercial support.
2. Which speech-to-text model is best for multilingual transcription?
Whisper supports 99 languages, while NVIDIA Nemo Canary excels in English, German, French, and Spanish. The choice depends on specific language needs and accuracy requirements.
3. Do these speech-to-text models work in noisy environments?
Yes, models like Whisper and Deepgram are specifically designed to handle background noise and various acoustic environments with good accuracy.


Sharmila Ananthasayanam
I'm an AIML Engineer passionate about creating AI-driven solutions for complex problems. I focus on deep learning, model optimization, and Agentic Systems to build real-world applications.





{kind=link}