

The advancements in large language models (LLMs) have opened new frontiers for natural language processing, but these models often require adaptation to meet specific use cases. Two prevalent techniques for this purpose are LLM Fine-Tuning and Retrieval-Augmented Generation (RAG).
While both enhance LLM capabilities, they do so in fundamentally different ways, making each approach suitable for specific scenarios. This blog delves into the mechanics, advantages, drawbacks, and use cases of both methods, offering a detailed comparison to help you decide which is right for your needs.
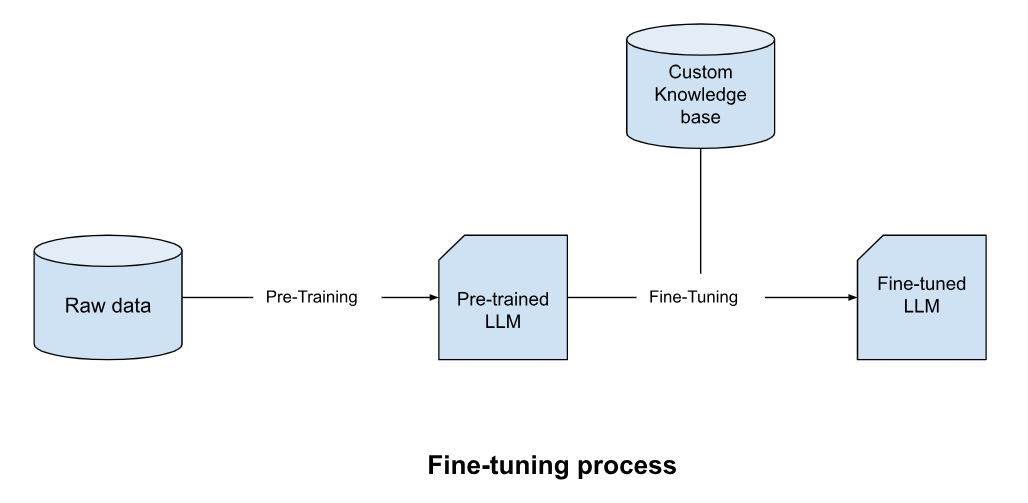
What is LLM Fine-Tuning?
Fine-tuning involves training a pre-trained LLM on a smaller, specialized dataset. This process adjusts the model's internal parameters to align with the nuances of a specific domain or task. For instance, a general-purpose model like GPT can be fine-tuned on legal documents to enhance its understanding of legal terminology and case analysis.
Key Features
- Task Specialization: Fine-tuning refines the model for a specific domain, ensuring high accuracy for targeted tasks.
- Static Learning: The model's knowledge remains fixed after fine-tuning, requiring retraining to incorporate new information.
- Resource-Intensive: Requires high-quality datasets and substantial computational resources during training.
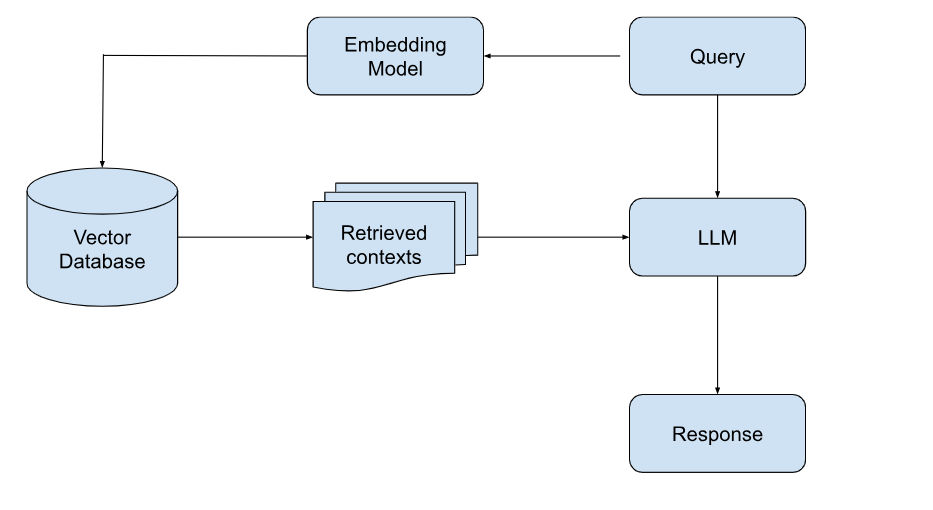
What is Retrieval-Augmented Generation (RAG)?
RAG combines a pre-trained LLM with a retrieval system. When a query is submitted, the system retrieves relevant information from an external knowledge base and feeds it into the model for context-aware response generation. This method is dynamic, allowing the model to access and integrate up-to-date information. If you’d like a deeper look at how this works in practice, here’s a detailed guide on Retrieval augmented generation rag that explains its core components, architecture, and real-world examples.
Key Features
- Dynamic Learning: By querying external databases in real-time, RAG can handle scenarios involving rapidly changing information.
- Knowledge Integration: Merges pre-trained model knowledge with real-world, up-to-date data.
- Lower Training Costs: Reduces the need for specialized datasets, focusing instead on robust retrieval mechanisms.
An example that illustrates the difference in performance of a language model before and after integrating Retrieval-Augmented Generation (RAG) can be seen in knowledge-intensive tasks, such as answering questions about new or highly specific domains.
Imagine a large language model (LLM) asked, "What are the symptoms of the latest flu variant that emerged in January 2024?"
Before RAG Integration
A standalone LLM might provide a generic answer based on its pre-trained knowledge, such as: "Common flu symptoms include fever, cough, sore throat, body aches, fatigue, and chills."This response, while broadly accurate, lacks specificity about the new flu variant because the model's knowledge cutoff predates its emergence.
After RAG Integration:
When integrated with RAG, the LLM can retrieve up-to-date medical records or recent articles about the flu variant. The answer might look like: "Symptoms of the latest flu variant, detected in January 2024, include high fever, persistent cough, and severe fatigue, along with unique symptoms such as conjunctivitis and nausea observed in a subset of cases."
This enhanced response is possible because RAG retrieves contextually relevant, external knowledge from sources like recent medical studies or news reports, which the LLM incorporates into its output. This approach eliminates the need to retrain the model, significantly enhancing its utility for dynamic, real-world scenarios.
RAG enables LLMs to adapt to evolving knowledge without extensive retraining, making them particularly valuable in domains where information changes frequently, such as healthcare or technical support.

Walk away with actionable insights on AI adoption.
Limited seats available!
Detailed Comparison: LLM Fine-Tuning vs RAG
| Aspect | Fine-Tuning | RAG |
Knowledge Integration | Static, fixed after training | Dynamic, continuously updated via external sources |
Flexibility | Limited to pre-defined tasks | Broadly applicable, adapts to varied queries |
Accuracy | High for specific domains | High in contexts requiring real-time or extensive external knowledge |
Cost and Resources | High initial computational cost; low inference cost | Moderate integration cost; higher inference cost due to retrieval mechanisms |
Use Cases | Niche domains like legal, medical, or financial document analysis | Open-domain Q&A, dynamic knowledge bases, and real-time data retrieval applications |
Pros and Cons of LLM Fine-Tuning and RAG
LLM Fine-Tuning
Pros
- Task-Specific Optimization: Fine-tuned models excel at specific tasks or domains, such as legal or medical language, producing highly relevant outputs tailored to specific use cases.
- Low Latency: Unlike retrieval-augmented generation (RAG), fine-tuned models do not require external retrieval processes, making their responses faster at inference time.
- Cost Efficiency in Use: While the initial setup is resource-intensive, serving a fine-tuned model is generally less expensive as it does not rely on additional query-time computations.
- Custom Style and Tone: Fine-tuning allows models to adopt specific writing styles or tones, which is beneficial for applications like personalized content generation or brand-specific interactions.
Cons
- High Setup Costs: Fine-tuning requires significant resources, including a high-quality dataset and computational power for retraining the model.
- Static Knowledge: Once fine-tuned, the model cannot incorporate new knowledge dynamically without additional retraining. For specific applications like improving SQL queries with fine-tuning, this static nature can be both an advantage and limitation depending on your use case.
- Risk of Overfitting: Fine-tuned models can become overly reliant on their training data, potentially failing to generalize to slightly different scenarios.
- Catastrophic Forgetting: When fine-tuned for specific tasks, a model may lose some of its previously acquired general-purpose knowledge.
Retrieval-Augmented Generation (RAG)
Pros
- Dynamic Knowledge Integration: RAG allows models to fetch and utilize the latest information from external databases, ensuring responses are current and contextually accurate.
- Wide Domain Coverage: RAG systems can handle a diverse range of queries by pulling information from broad and varied sources.
- Cost-Effective for Data Updating: Unlike fine-tuning, which requires retraining for new information, RAG leverages external updates in real-time without modifying the model.
- Scalability: By separating retrieval and generation processes, RAG offers flexibility in adapting to new datasets or domains.
Cons
- Higher Inference Costs: The dependency on external retrieval mechanisms and larger prompt sizes increases computational overhead during inference.
- Latency: Incorporating retrieval processes can slow down response times compared to fine-tuned models.
- Complex Integration: RAG systems require expertise in database management, information retrieval techniques, and query optimization for effective deployment.
- Context Size Limitations: The inclusion of retrieved information can quickly exhaust the model's token limit, posing challenges for handling extensive queries.
Choosing Between the Two
Fine-tuning is ideal for highly specialized applications where efficiency and domain-specific expertise are paramount, such as automated legal document drafting or sentiment analysis in specific industries. On the other hand, RAG excels in scenarios requiring up-to-date information, like chatbots addressing current events or tools retrieving the latest market data
When to Use Fine-Tuning vs. RAG (Retrieval-Augmented Generation)
Choosing between fine-tuning and Retrieval-Augmented Generation (RAG) depends on the specific requirements of your application. Here’s a detailed guide on when each method is most suitable:
Fine-Tuning: Best for Specialized, Static Use Cases
Domain Expertise and Precision:
- Fine-tuning excels when your application requires domain-specific knowledge, such as legal, medical, or technical fields. By tailoring the model's parameters to your dataset, it achieves higher accuracy and precision for tasks like document analysis or sentiment detection.
- Examples include fine-tuned models for legal document analysis or tailored customer support bots where accuracy and adherence to regulations are crucial.
Consistency and Controlled Outputs:
- If your application demands consistent language, tone, or format, fine-tuning is ideal. For instance, a model fine-tuned to draft contracts will reliably adhere to predefined templates and legal language styles.
Stable and High-Quality Data:
- Fine-tuning is effective when the training data is robust, stable, and unlikely to change frequently. This reduces the need for re-tuning and ensures efficiency in operations.
Cost-Efficiency for High Query Volumes:
- While the training phase is resource-intensive, fine-tuning results in a model that is efficient to deploy for large-scale, repetitive queries. This makes it suitable for applications like personalized education systems or financial report generation where the cost of serving queries must remain low.
Walk away with actionable insights on AI adoption.
Limited seats available!
RAG: Best for Dynamic and Evolving Knowledge Bases
Real-Time and Up-to-Date Information:
- RAG connects models to dynamic knowledge bases, allowing them to generate answers based on the most current data. This is critical for applications like chatbots handling breaking news or customer inquiries that rely on live data.
- Example: A RAG-powered chatbot that pulls real-time inventory details for e-commerce.
Flexibility Across Domains:
- Since RAG dynamically retrieves context-specific information at inference time, it avoids the constraints of a static knowledge base. This is ideal for applications requiring diverse or cross-domain queries, such as virtual assistants or help desks.
Data Privacy and Control:
- RAG can keep sensitive or proprietary information within a secured environment by querying internal databases without embedding sensitive data into the model itself. It’s particularly useful for industries with strict data privacy laws, such as healthcare and finance.
Cost of Updating vs. Querying:
- Unlike fine-tuning, RAG doesn’t require retraining the model to incorporate new information. This reduces operational costs in environments where data evolves frequently, such as research repositories or legal case databases.
Combining Fine-Tuning and RAG (Hybrid Approach)
For organizations with diverse needs, a hybrid approach may be the best option:
- Use fine-tuning to build a model specialized for core operations or repetitive tasks requiring high precision.
- Combine it with RAG for broader, real-time queries that require flexibility and access to dynamic knowledge bases. This dual setup balances accuracy with adaptability, as fine-tuned models handle niche use cases while RAG addresses broader knowledge needs
Conclusion
Both fine-tuning and RAG are powerful tools for enhancing LLMs, but their applications and efficiencies differ significantly. Fine-tuning is your go-to for niche, domain-specific tasks requiring depth and precision, while RAG excels in dynamic environments needing up-to-date information and adaptability.
Deciding between the two depends on your project requirements, resource availability, and whether your task demands static expertise or real-time adaptability. By understanding their respective strengths and limitations, you can make an informed choice tailored to your use case.
For more information, explore detailed guides and tutorials on fine-tuning and RAG from platforms like Hugging Face, Acorn, and Cyces.
Frequently Asked Questions?
1. What's the main difference between fine-tuning and RAG?
Fine-tuning modifies the model's parameters for specific tasks, while RAG connects models to external knowledge bases for real-time information retrieval.
2. Which approach is more cost-effective?
Fine-tuning has higher initial costs but lower inference costs, while RAG has lower setup costs but higher ongoing operational costs due to retrieval processes.
3. When should I choose RAG over Fine-Tuning?
Choose RAG when you need real-time information updates, flexible knowledge integration, and don't want to retrain the model frequently.

Kiruthika
I'm an AI/ML engineer passionate about developing cutting-edge solutions. I specialize in machine learning techniques to solve complex problems and drive innovation through data-driven insights.
Walk away with actionable insights on AI adoption.
Limited seats available!


