If you've ever wondered how computers understand words, sentences, or images, you're about to find out! Embedding models might sound complex, but they're actually pretty neat - they're like translators that turn human concepts into numbers that machines can work with.
In this easy-to-understand guide, we'll break down what embeddings are, why they matter, and how they work. Whether you're a curious beginner or looking to implement embeddings in your projects, we've got you covered with simple explanations and practical examples!
What Is an Embedding?
An embedding is a way of turning things (like words, sentences, or images) into numbers so that computers can understand them.
Imagine you’re trying to describe the concept of "cat" to a computer. For humans, we know cats are furry, have tails, and love naps. But for a computer, we need to translate that understanding into a numerical format, like [0.4, 0.8, 0.1, 0.7].
Embeddings capture the meaning or context of data (like the relationship between "cat" and "kitten") in a numerical form that machines can use to:
- Compare things (e.g., how similar "cat" and "dog" are).
- Perform tasks like searching, recommending, or classifying.
Why and When Are Embeddings Used?
Embeddings are used when we need to understand the meaning or relationships between things in data.
Reduce Complexity
Instead of dealing with raw data like millions of words, embeddings simplify the information into compact vectors.
Think of it like making a recipe card instead of keeping the entire cookbook. Instead of dealing with entire sentences or documents, embeddings create a short "summary" in numbers. For example, rather than processing the whole word "pizza" with all its letters, we might represent it as [0.2, 0.8, 0.5] - much simpler for computers to handle!
Find Similarities
They help in comparing data, like matching similar sentences in search engines. Many of these similarity checks are powered by machine learning models that learn how concepts relate to each other.
It's like having a smart library assistant who can tell you, "If you liked Harry Potter, you might enjoy Percy Jackson" because they share similar themes and elements. Embeddings help computers make these connections by comparing their number patterns. When Netflix suggests shows you might like, it's often using embeddings to find similar content.
Enable Machine Learning
Machine learning models rely on numerical input, and embeddings make this possible by converting text, images, or other data into meaningful numerical representations. These vectors capture patterns and relationships, allowing models to understand similarity, context, and intent.

Walk away with actionable insights on AI adoption.
Limited seats available!
In real-world applications, embeddings power features like search, recommendations, clustering, and classification by helping systems compare data more effectively.
Computers can’t directly understand words or images, they need numbers to process them. Embeddings act as a translation layer, turning human language and content into a format machines can work with.
Common Scenarios of Embedding
Search Engines
To rank results based on how relevant they are to your query.
Example: When you search for “best pizza near me,” embeddings help the system understand intent, not just keywords. Instead of matching exact phrases, it identifies related concepts like “top-rated pizzerias” or “Italian restaurants nearby,” improving the relevance of results.
Recommendation Systems
To suggest similar items, like movies or books
Ever wondered how Spotify knows what music to suggest? When you listen to Taylor Swift, embeddings help identify songs with similar patterns, moods, or styles. That's why you might get recommendations for similar pop artists or songs with matching emotional tones.
Natural Language Processing (NLP)
Tasks like sentiment analysis, translation, or text classification.
Think of how Gmail completes your sentences or how chatbots understand you. Embeddings help computers understand if an email is spam if a tweet is positive or negative, or translate "hello" to "bonjour" by understanding the meaning behind words.
Computer Vision
For tasks like finding similar images.
When you upload a photo to Pinterest and it shows similar images, that's embeddings at work! They help computers understand that a picture of a golden retriever puppy is similar to other dog photos, even if they look slightly different.
What Do Embedding Models Do?
Embedding models are trained to create these meaningful numerical representations (vectors). Depending on the type of data, embedding models can process:
- Words or Phrases: Models like Word2Vec represent individual words as embeddings.
- Sentences or Paragraphs: Models like Sentence-BERT handle longer text and capture their overall meaning.
- Images: Vision embedding models like CLIP generate embeddings for images.
Once you have these embeddings, you can perform operations like clustering, searching, or comparing data.
Commonly Used Embedding Models
Here are some popular embedding models and what they’re good at:
- Word2Vec: One of the earliest word embedding models, capturing relationships like "king - man + woman = queen."
- BERT (Bidirectional Encoder Representations from Transformers): A powerful NLP model that generates contextual embeddings.
- sentence-transformers/all-MiniLM-L6-v2: This is a sentence-transformers model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
- Jina-embeddings-v3: Multilingual multi-task text embedding model designed for a variety of NLP applications.
- nomic-ai/nomic-embed-text-v1: A Reproducible Long Context (8192) Text Embedder.
Walk away with actionable insights on AI adoption.
Limited seats available!
When implementing these models in real-world applications, embeddings are typically served through APIs. Choosing the right API design is important to ensure efficient data delivery, scalability, and low latency for client applications.
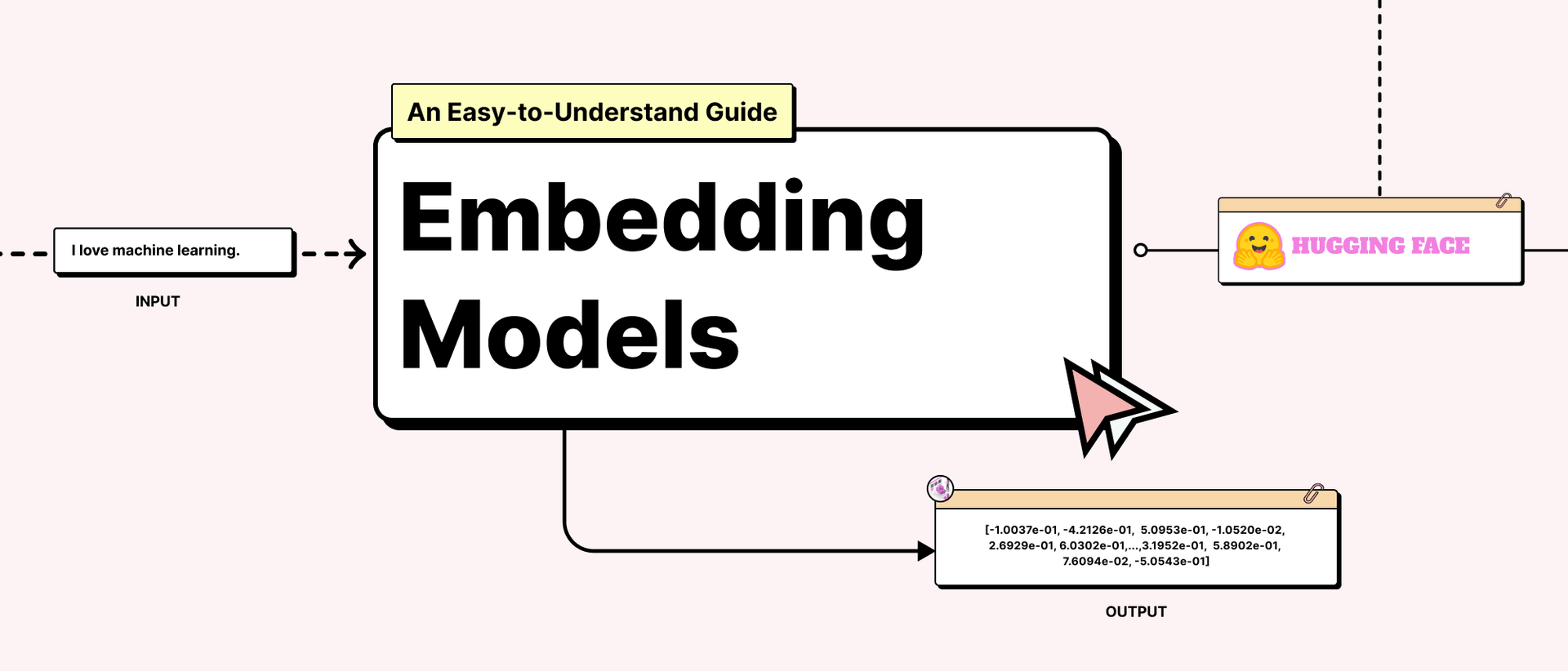
Embedding Model Example Code (Using Hugging Face for Embeddings)
Let’s see how you can use an embedding model with Hugging Face’s Transformers library. We’ll use Sentence-BERT (SBERT) to generate sentence embeddings. You can also build a simple interface using tools like Gradio to test and visualize embeddings interactively.
from transformers import AutoTokenizer, AutoModel
import torch
# Load a pre-trained embedding model from Hugging Face
model_name = "sentence-transformers/all-MiniLM-L6-v2" # A lightweight SBERT model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
# Input sentences
sentences = ["I love machine learning.", "Artificial Intelligence is fascinating!"]
# Tokenize the input
inputs = tokenizer(sentences, padding=True, truncation=True, return_tensors="pt")
# Generate embeddings
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1) # Take the mean across token embeddings
# Print embeddings
print("Sentence Embeddings:")
for i, embedding in enumerate(embeddings):
print(f"Sentence {i+1}: {embedding}")
Output:
Sentence Embeddings:
Sentence 1: tensor([-1.0037e-01, -4.2126e-01, 5.0953e-01, -1.0520e-02, 2.6929e-01, 6.0302e-01,...,3.1952e-01, 5.8902e-01, 7.6094e-02, -5.0543e-01])
Sentence 2: tensor([-3.7269e-02, -4.1528e-01, 3.4694e-01, 6.7872e-03, -4.6158e-02,..., 3.9135e-01, 8.6889e-01,4.8454e-01, 5.1503e-01, 5.3607e-02, -3.8725e-01])
Code Explanation
- We loaded a Sentence-BERT model using Hugging Face.
- We tokenized sentences into a format the model understands.
- We passed these tokens to the model to get their embeddings.
- Finally, we printed the numerical embeddings, which represent the sentences in vector form. These vectors can now be used for tasks like similarity search, clustering, or recommendation systems.
Our Final Words
Embedding models are like translators between human concepts and machine-readable numbers. They power a wide range of applications, from chatbots to search engines and beyond.
If you’re just starting, tools like Hugging Face make it incredibly easy to experiment with embeddings. Grab a pre-trained model, feed it some data, and see the magic for yourself!
Have fun embedding your knowledge into the world of AI! 😊
Frequently Asked Questions?
1. Do I need advanced math to work with embeddings?
While embeddings use mathematical concepts, modern libraries and tools make it easy to get started. You can use pre-trained embedding models without diving deep into the math, just like using a calculator without knowing how it works internally.
2. How do I choose the right embedding model for my project?
The choice depends on your needs: for simple text tasks, models like Word2Vec might be enough. For more complex language understanding, BERT or Sentence-BERT are better choices. Consider factors like data type (text/images), language support, and processing speed.
3. Are embeddings only for large-scale applications?
Not at all! Embeddings can be useful even for small projects. Whether you're building a simple search feature for a website or categorizing customer feedback, embeddings can help improve accuracy and user experience.

Sharmila Ananthasayanam
I'm an AIML Engineer passionate about creating AI-driven solutions for complex problems. I focus on deep learning, model optimization, and Agentic Systems to build real-world applications.
Walk away with actionable insights on AI adoption.
Limited seats available!


