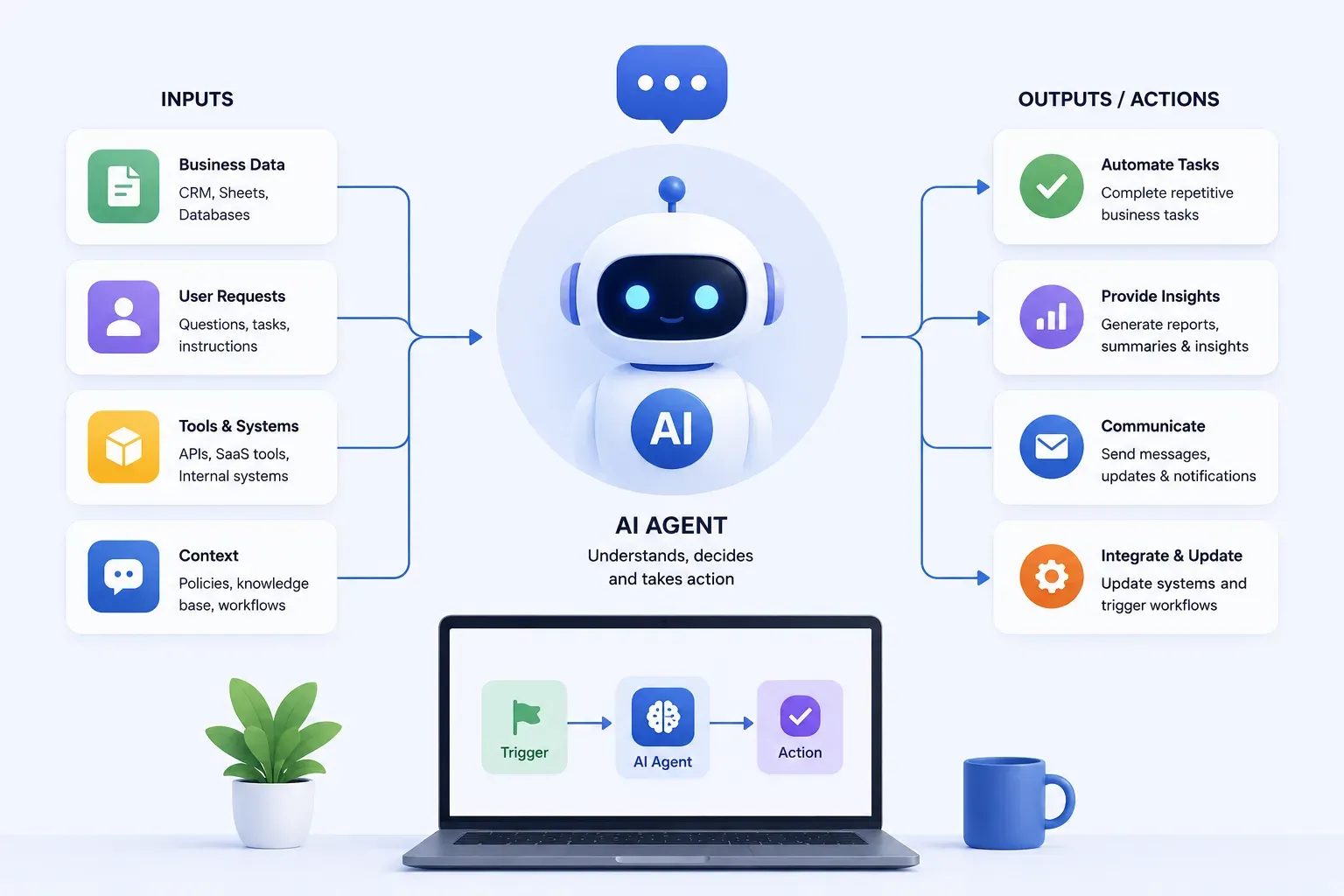
AI tools that write emails, answer questions, summarize documents, and translate languages all have one thing in common: they are powered by large language models. These systems have moved from research labs into everyday software, but most people using them have no clear picture of what they actually are or how they work.
This guide explains what a large language model is, what it can do, how inference works, and where the technology still falls short.
What Is a Large Language Model (LLM)?
A large language model is a type of artificial intelligence trained on massive amounts of text data to understand, process, and generate human language. It learns patterns across billions of sentences and uses those patterns to predict what words should come next given a particular context.
In practical terms, this means an LLM can answer questions, summarize documents, translate languages, write content, and generate code, all from a plain language prompt. Popular examples include GPT-4, Claude, Gemini, Mistral, and LLaMA.
What Are LLMs Used For?
Large language models are used across industries because they handle language tasks at a scale and speed that manual processes cannot match.
Content generation. LLMs draft blog posts, product descriptions, emails, and reports quickly and with strong contextual coherence.
Translation. They convert text between languages while preserving tone and meaning, not just word-for-word substitution.
Summarization. Long documents, research papers, and meeting transcripts can be condensed into key points in seconds.
Sentiment analysis. LLMs identify emotional tone in customer reviews, support tickets, and social media conversations.
Question answering. They extract relevant answers from large knowledge bases or generate responses based on retrieved context.
Text classification. LLMs organize content into categories, such as tagging support tickets by topic or sorting research papers by subject area.
Because they work with language patterns rather than rigid rules, LLMs can adapt to many different workflows without requiring task-specific retraining.
Why Large Language Models Matter
LLMs matter because they change how humans and machines work with language at scale, across three areas in particular.
Productivity. They automate time-consuming tasks like drafting, summarizing, and analyzing text, freeing professionals to focus on higher-order thinking and decision-making.
Access to information. Through translation, summarization, and question answering, LLMs make complex information easier to understand and more accessible across languages and literacy levels.
Smarter applications. Modern AI assistants, intelligent search systems, customer support bots, and content platforms are all built on LLMs as their core engine. As the models improve, so do the products built on top of them.

Walk away with actionable insights on AI adoption.
Limited seats available!
What Is LLM Inference?
Inference is the process of using a trained model to generate outputs on new input. It is the practical phase of machine learning, where everything the model learned during training gets applied to real queries.
For a large language model, inference happens every time a user submits a prompt. The model processes the text, applies the patterns it learned during training, and generates a response. This is what powers chatbots, AI search tools, content generators, and voice assistants.
How inference works in three steps:
- Input: A user provides a prompt or query to the model.
- Processing: The model analyzes the input using patterns learned during training.
- Output: The model generates a response based on that analysis.
No new learning happens during inference. The model simply applies its existing knowledge to produce an output.
Training vs Inference: What Is the Difference?
Training and inference are two distinct phases in the machine learning lifecycle.
During training, the model is shown large amounts of labelled data and adjusts its internal parameters to learn patterns. This is computationally intensive and typically requires multiple GPUs running for days or weeks.
During inference, those parameters are fixed. The model applies what it learned to new inputs. Inference is faster and can run on less powerful hardware than training requires.
A practical example: a spam classifier is trained on thousands of labelled emails to learn what spam looks like. Once trained, it uses that knowledge to classify new emails it has never seen before. The training phase is done. Inference runs continuously every time a new email arrives.
For LLMs, the same principle applies. Training is how the model learns language. Inference is how the model responds to you.
Advantages of Large Language Models
Accuracy across multiple tasks. Modern LLMs can summarize, translate, answer questions, and generate content with strong contextual accuracy. Their ability to learn from patterns across enormous datasets allows them to handle a wide range of real-world scenarios reliably.
Multi-task capability. A single LLM can draft emails, analyze sentiment, explain code, and assist with research, all without switching models. This reduces the need for separate specialized tools for every task.
Scalability. LLMs can process large volumes of text quickly, making them suitable for enterprise environments where thousands of interactions happen daily. They enable automation at a scale that manual processes cannot match.
Context-aware responses. LLMs interpret context rather than just detecting keywords. This allows them to maintain conversational flow, adapt to user intent, and generate responses that feel natural rather than mechanical.
Foundation for AI applications. Intelligent search, chatbots, digital assistants, and knowledge retrieval systems all rely on LLMs as their core engine. Their versatility makes them the backbone of the modern AI product landscape.
Limitations of Large Language Models
High computational requirements. Training and running advanced LLMs require significant computing power, memory, and high-quality data. This makes development expensive and can limit access for smaller organizations.
Cost at scale. Beyond training, maintaining and deploying LLMs in production can be costly. Ongoing compute usage, API costs, and infrastructure requirements create real barriers for startups and small teams.
Bias from training data. LLMs learn from data collected from the internet and other sources. If that data contains social, cultural, or gender biases, the model may reflect those biases in its outputs. Addressing this requires careful dataset curation and ongoing monitoring.
Inconsistent outputs. LLMs are probabilistic. The same prompt can produce slightly different responses at different times. This flexibility is useful in creative contexts but can reduce reliability in applications requiring consistent outputs.
Limited interpretability. LLMs are complex neural networks. It is difficult to fully understand how they arrive at specific outputs. In high-stakes environments like healthcare or legal analysis, this lack of transparency is a real constraint on adoption.
Walk away with actionable insights on AI adoption.
Limited seats available!
Conclusion
Large language models have changed how machines process and generate human language. They power content creation, translation, intelligent search, and automation at a scale that was not possible before.
Their strength is versatility: one model handles many tasks. Their limitations, including computational cost, potential bias, and inconsistent outputs, make responsible deployment just as important as the technology itself. Understanding both sides is what separates effective use from naive reliance.
Frequently Asked Questions
What is a large language model?
A large language model is an AI system trained on massive amounts of text data to understand and generate human language. It predicts the most likely next words given a context and uses that capability to answer questions, summarize content, translate text, and more.
How do large language models work?
LLMs are trained on billions of text examples to learn statistical patterns in language. When given a prompt, they process the input and generate a response by predicting what words are most likely to follow, based on those learned patterns.
What are large language models used for?
LLMs are used for content generation, translation, summarization, sentiment analysis, question answering, text classification, and as the foundation for AI assistants, chatbots, and intelligent search systems.
What is the difference between LLM training and inference?
Training is the process of teaching the model by adjusting its parameters on large datasets. Inference is the process of using the trained model to generate outputs on new inputs. Training is done occasionally. Inference runs continuously whenever the model is in use.
What are the limitations of large language models?
Key limitations include high computational requirements, potential bias from training data, inconsistent outputs due to probabilistic generation, limited interpretability, and significant cost at scale.
What are some examples of large language models?
Popular LLMs include OpenAI's GPT-4, Anthropic's Claude, Google's Gemini, Meta's LLaMA, and Mistral. Each has different strengths, context limits, and intended use cases.

Walk away with actionable insights on AI adoption.
Limited seats available!