

Data engineering is the art and science of designing, constructing, and maintaining the systems that collect, store, and process vast amounts of data. It's the foundation upon which modern data-driven organizations build their insights and make critical decisions. As a data engineer, I've witnessed firsthand how this field has evolved from simple data management to complex, real-time data processing ecosystems.
In essence, data engineering is about creating robust, scalable infrastructures that can handle the ever-growing volume, velocity, and variety of data. It's about transforming raw, unstructured data into valuable, actionable insights that can drive business strategies and fuel innovation.
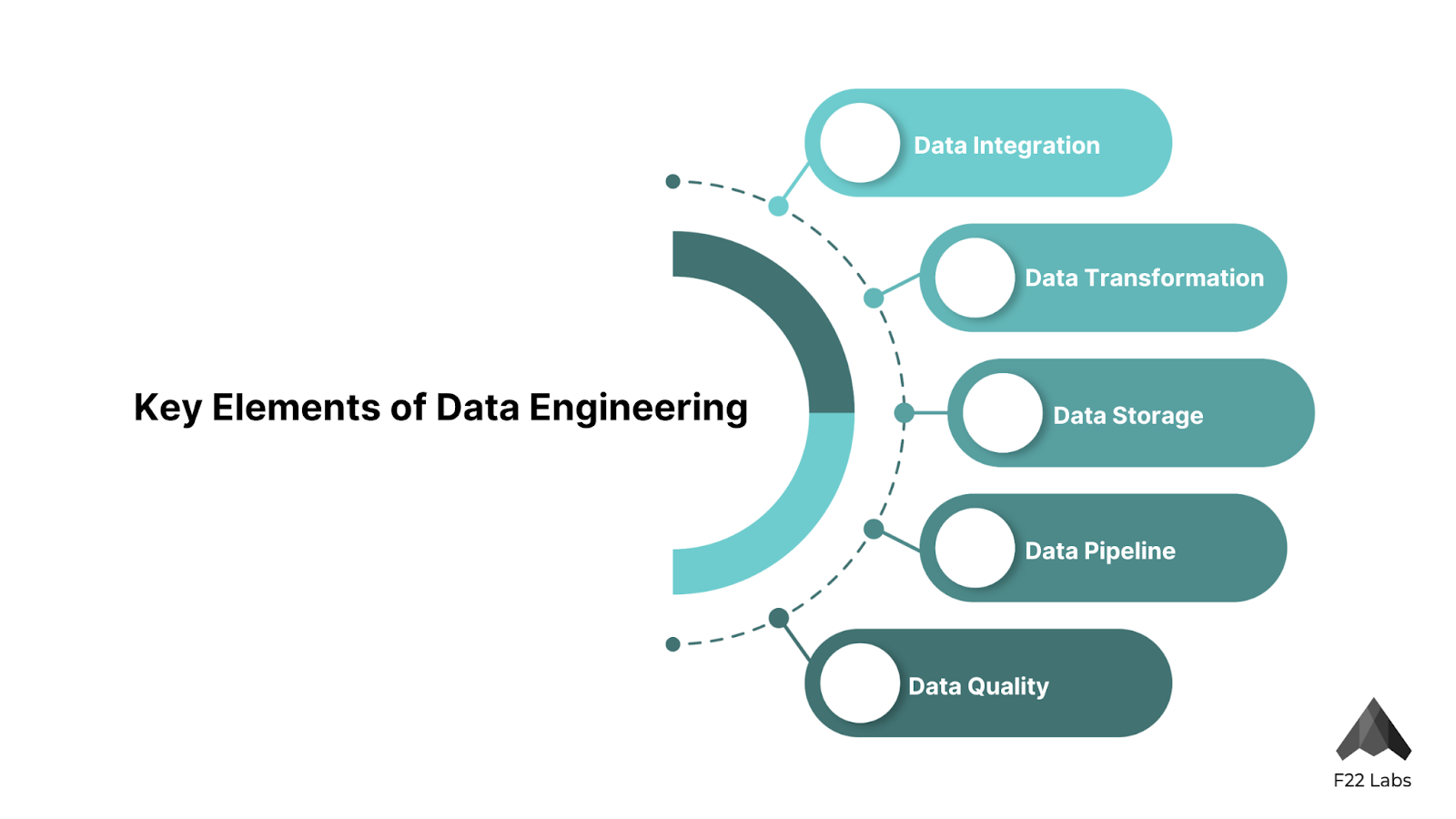
Key Elements of Data Engineering
The world of data engineering is multifaceted, encompassing various elements that work together to create a seamless data flow. Let's break down these key components:
- Data Integration: This is the process of combining data from multiple sources into a unified view. It's like assembling a giant puzzle, where each piece of data needs to fit perfectly with the others. In my experience, mastering data integration is crucial for providing a holistic view of an organization's operations.
- Data Transformation: Raw data is often messy and inconsistent. Data transformation is the process of cleaning, structuring, and enriching this data to make it suitable for analysis. It's like refining crude oil into usable fuel – it takes skill, precision, and the right tools.
- Data Storage: With the explosion of big data, efficient storage solutions have become more critical than ever. From traditional relational databases to modern data lakes, choosing the right storage solution can make or break a data engineering project.
- Data Pipeline: This is the heart of data engineering. A data pipeline is an automated series of processes that move data from its source to its final destination. Building robust, scalable pipelines is an art form that I've spent years perfecting.
- Data Quality: Ensuring the accuracy, completeness, and consistency of data is paramount. After all, even the most sophisticated analysis is worthless if it's based on faulty data.
As the field of data engineering has grown, so too have the specializations within it. In my career, I've encountered several types of data engineers, each with a unique focus:
- Pipeline Engineers: These are the architects of data flow. They design and build systems that move data from one point to another, ensuring smooth and efficient data transfer.
- Database Engineers: These specialists focus on designing, implementing, and maintaining database systems. They're the guardians of data storage, ensuring that data is stored efficiently and can be retrieved quickly when needed.
- Analytics Engineers: Bridging the gap between data engineering and data analysis, these professionals prepare data specifically for analytical use. They work closely with data scientists and analysts to ensure that data is in the right format for advanced analytics.
- Machine Learning Engineers: As AI and machine learning have become increasingly important, so too have engineers specializing in building data infrastructure for ML models. They ensure that data pipelines can handle the unique demands of machine learning algorithms.
I've found that having a broad understanding of all these areas before specializing has been invaluable. It's allowed me to see the big picture and create more integrated, efficient data systems.
Key Data Engineering Skills
The field of data engineering is ever-evolving, and staying on top of the latest skills and technologies is crucial. Here are some of the key skills I've found to be indispensable:
- Programming: Proficiency in languages like Python, Java, or Scala is a must. These languages are the building blocks of most data engineering tasks. I remember when I first started, I was primarily using Java. Now, Python has become my go-to language for its versatility and extensive libraries.
- Database Management: A deep understanding of both SQL and NoSQL databases is crucial. Each has its strengths, and knowing when to use which is a skill that comes with experience.
- Big Data Technologies: Familiarity with tools like Hadoop, Spark, and Kafka is essential in today's big data landscape. I've seen these technologies revolutionize how we handle and process large volumes of data.
- Cloud Computing: With the shift towards cloud-based solutions, experience with platforms like AWS, Google Cloud, or Azure has become increasingly important. The cloud has opened up new possibilities in terms of scalability and flexibility.
- Data Modeling: The ability to design efficient data structures is a core skill. It's about understanding how data relates to each other and how it can be organized for optimal use.
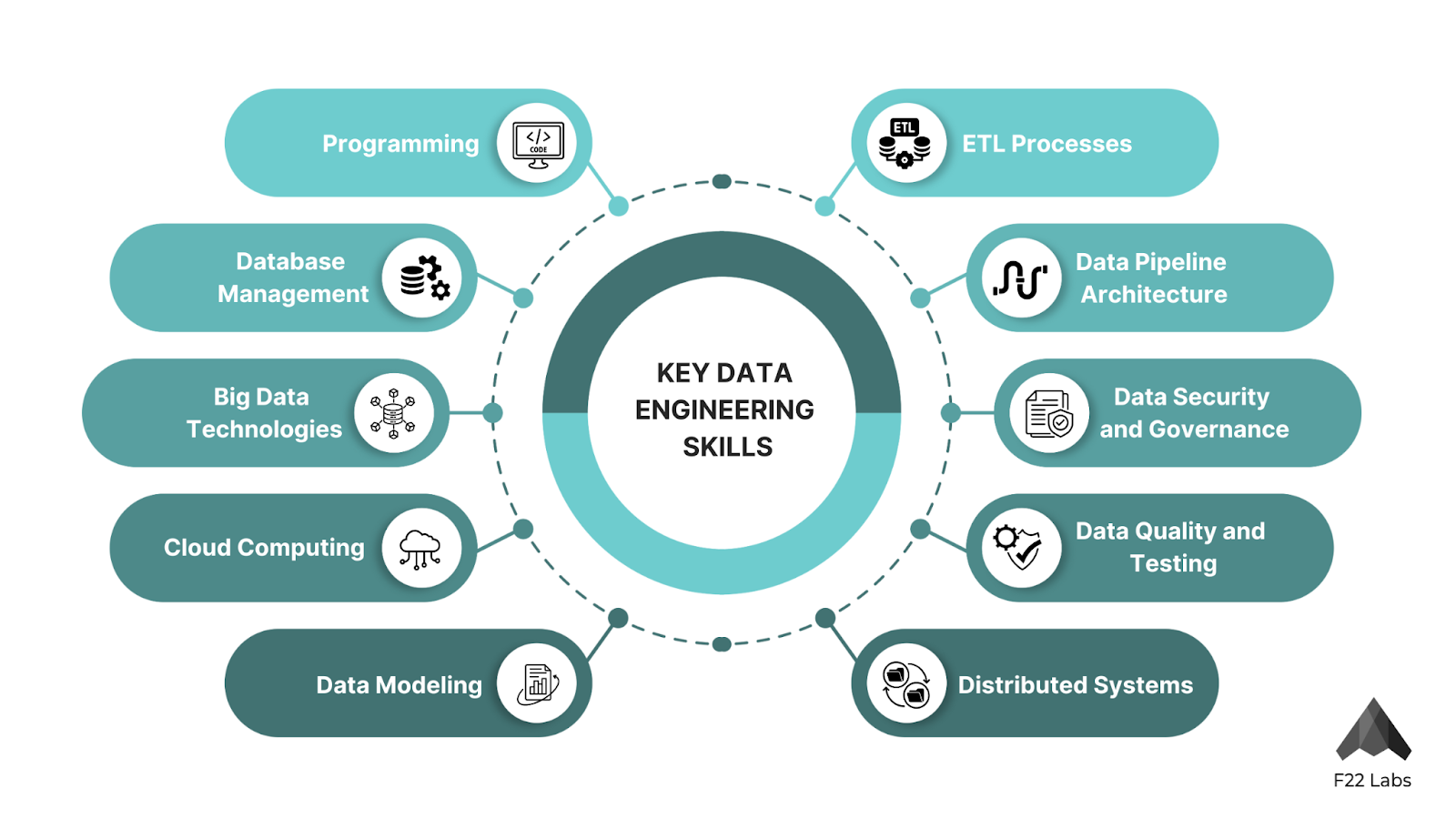
- ETL Processes: Understanding Extract, Transform, Load operations is fundamental. It's the bread and butter of data movement and preparation.
- Data Pipeline Architecture: This is a skill I've honed over time, and it's become increasingly critical. Designing robust, scalable data pipelines isn't just about moving data from point A to point B. It's about creating a flexible, fault-tolerant system that can handle varying data volumes, velocities, and varieties. I remember a project where we underestimated the growth of incoming data. Our pipeline quickly became a bottleneck, causing delays in reporting and analytics. That experience taught me the importance of future-proofing pipeline designs. Now, I always architect with scalability in mind, using technologies like Apache Kafka for real-time streaming and Airflow for workflow management.
- Data Security and Governance: In today's world of data breaches and strict privacy regulations like GDPR and CCPA, this skill has become non-negotiable. It's not just about protecting data from external threats; it's also about ensuring proper access controls within the organization. I've implemented data governance frameworks that track data lineage, manage metadata, and ensure compliance with data privacy laws. Tools like Apache Atlas for data governance and AWS KMS for encryption have been game-changers in this area.
- Distributed Systems: As data volumes grow, the ability to work with distributed systems becomes crucial. Understanding concepts like partitioning, replication, and consensus algorithms is vital for building systems that can handle massive scale. My experience with technologies like Apache Cassandra and Elasticsearch has been invaluable here. I once worked on a project where we needed to process billions of events daily. Implementing a distributed system using Cassandra for storage and Spark for processing allowed us to achieve the scale and performance we needed.
- Data Quality and Testing: Ensuring data quality is an often overlooked but critical skill. It's not just about writing unit tests for your code; it's about implementing data quality checks throughout your pipeline. I've developed comprehensive data quality frameworks that check for completeness, accuracy, consistency, and timeliness of data. Tools like Great Expectations have been a boon in this area, allowing us to define and enforce data quality expectations programmatically.
Data Engineering Use Cases
I've seen data engineering applied in numerous exciting ways across various industries. Let me share some of the most impactful use cases I've encountered:
- Real-time Fraud Detection: One of the most critical applications I've worked on was for a major financial institution. We built a system that could analyze transactions in milliseconds, comparing them against historical patterns and known fraud indicators.
- Recommendation Engines: These systems require processing vast amounts of user behavior data, product information, and historical purchase data. The data pipelines we built could handle millions of events per second, allowing for real-time personalized recommendations that significantly boosted conversion rates.
- IoT Data Processing: In a project for a smart city initiative, we designed a system to handle massive streams of sensor data from traffic lights, parking meters, and public transportation. This real-time data processing allowed for dynamic traffic management and improved urban planning.
- Customer 360 Views: For a telecom company, we created a comprehensive customer data platform that integrated data from various touchpoints - call centers, mobile apps, website interactions, and billing systems. This unified view enabled personalized customer experiences and more effective marketing campaigns.
- Predictive Maintenance: In the manufacturing sector, I worked on a system that used data from IoT sensors on factory equipment to predict potential failures before they occurred. This proactive approach to maintenance significantly reduced downtime and maintenance costs.
Streaming Vs Batch Processing
We often deal with two main types of data processing: streaming and batch. Each has its place, and understanding when to use it is crucial.
Partner with Us for Success
Experience seamless collaboration and exceptional results.
Batch Processing: This is like doing your laundry - you wait until you have a full load before running the washer. In data terms, it means processing data in large chunks at scheduled intervals.
- Pros: Can handle very large volumes of data efficiently, less complex to implement
- Cons: Introduces latency, not suitable for real-time applications
- Use cases: Daily sales reports, monthly financial statements, periodic data backups
Stream Processing: This is more like washing dishes as you use them. It processes data in real-time as it arrives.
- Pros: Low latency, ideal for real-time applications
- Cons: More complex to implement, can be more resource-intensive
- Use cases: Fraud detection, real-time analytics dashboards, live recommendations
The choice between streaming and batch often depends on the specific use case and business requirements. I've seen hybrid approaches work well too, where we use stream processing for time-sensitive data and batch processing for less urgent, high-volume data.
Data Engineering Terms
Let me break down some key terms every data engineer should know:
- ETL: Extract, Transform, Load - the process of moving data from source systems to a data warehouse
- Data Lake: A repository for storing large amounts of raw, unstructured data
- Data Warehouse: A system for storing structured, processed data for easy querying and analysis
- Data Pipeline: An automated series of data processing steps
- Data Mart: A subset of a data warehouse focused on a specific business area
- Schema: The structure that defines how data is organized in a database
- API: Application Programming Interface, often used for data exchange between systems
- Hadoop: An ecosystem of open-source tools for distributed storage and processing of big data
- Spark: A fast, distributed processing system for large-scale data processing
How Does Data Engineering Work?
The data engineering process typically follows these steps:
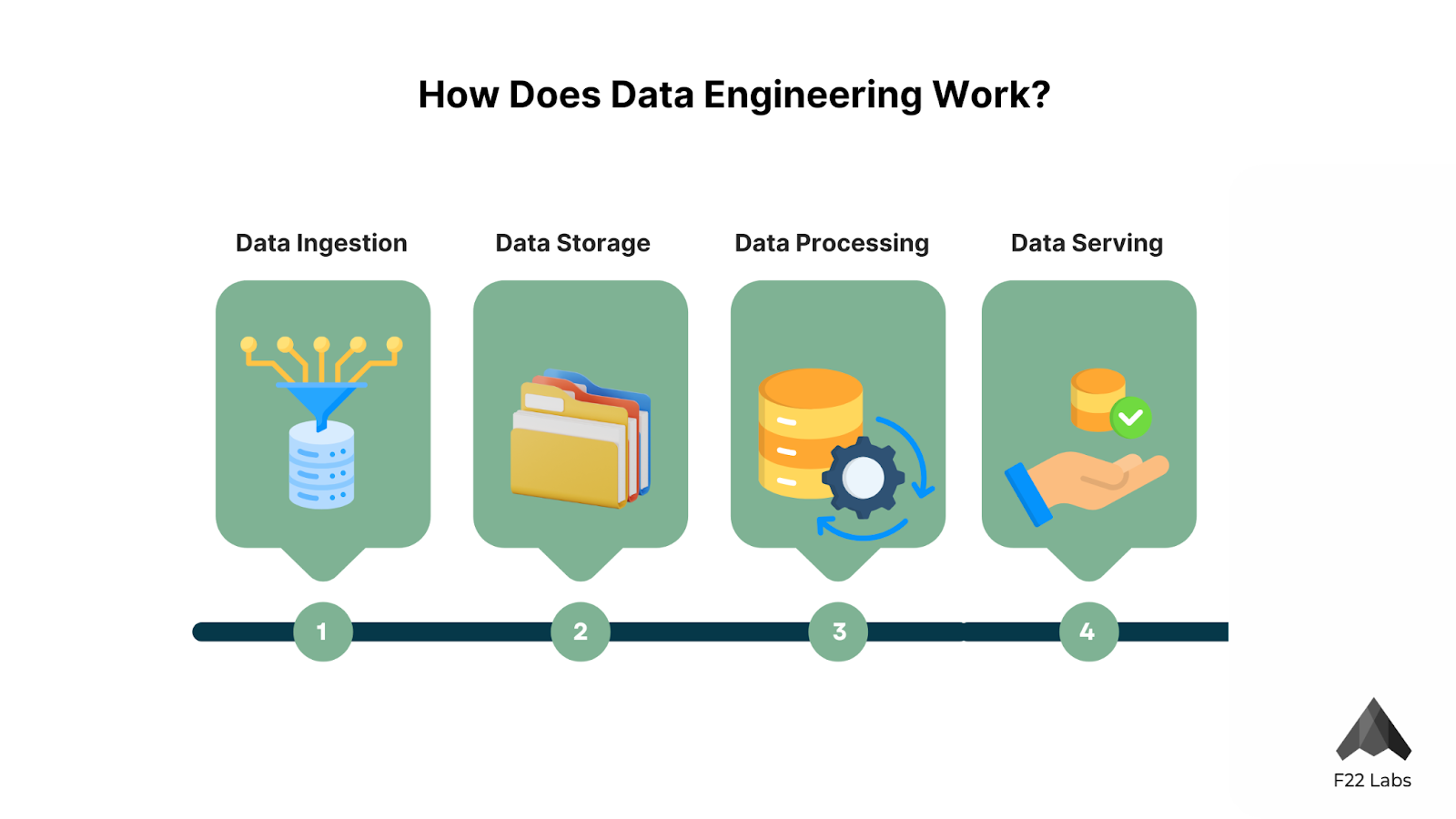
- Data Ingestion: This is where we collect data from various sources. In one project, we were ingesting data from social media APIs, IoT devices, and traditional databases. The challenge was handling the different data formats and velocities.
- Data Storage: Once ingested, data needs to be stored. Depending on the nature of the data and its intended use, we might store it in a data lake for raw data or a structured data warehouse. I've used everything from Amazon S3 for data lakes to Snowflake for cloud data warehousing.
- Data Processing: This is where the magic happens. We clean the data, transform it into a usable format, and perform necessary calculations or aggregations. Tools like Apache Spark have been game-changers for processing large volumes of data efficiently.
- Data Serving: Finally, we make the processed data available for analysis or machine learning. This might involve loading it into a BI tool, exposing it via APIs, or feeding it into ML models.
Throughout this process, we implement data quality checks, monitor the pipelines for any issues, and ensure data security and compliance.
What is the Difference Between Data Engineering and Data Analysis?
While closely related, data engineering and data analysis serve different purposes:
Data Engineering:
- Focuses on building and maintaining data infrastructure
- Deals with large-scale data processing and storage
- Requires strong programming and system design skills
- Creates the foundation that makes data analysis possible
Data Analysis:
- Focuses on extracting insights from processed data
- Involves statistical analysis and data visualization
- Requires strong analytical and business acumen
- Uses the data infrastructure built by data engineers to derive business value
I like to think of it this way: data engineers build the race track, while data analysts are the drivers who navigate it to reach the finish line. Both are crucial for winning the race.
Which Data Tools Do Data Engineers Use?
I've worked with a wide array of tools. The landscape is constantly evolving, but here are some of the key tools that have been invaluable in my work:
- Apache Hadoop: This open-source framework has been a game-changer for distributed storage and processing of big data. I've used it extensively for projects involving petabytes of data. The Hadoop ecosystem includes tools like HDFS for storage and MapReduce for processing.
- Apache Spark: When it comes to large-scale data processing, Spark is my go-to tool. Its in-memory processing capabilities make it significantly faster than traditional MapReduce jobs. I've used Spark for everything from batch processing to real-time stream processing.
- Apache Kafka: For building real-time data pipelines, Kafka is unparalleled. I once used it to build a system that could process millions of events per second for a large e-commerce platform.
- Apache Airflow: This tool has revolutionized how we manage complex workflows. I use it to orchestrate data pipelines, ensuring tasks are executed in the right order and at the right time.
- PostgreSQL: While big data tools get a lot of attention, traditional relational databases still have their place. PostgreSQL has been my choice for projects requiring ACID compliance and complex transactions.
- MongoDB: For projects requiring flexibility in data structure, MongoDB has been invaluable. Its document-based structure allows for easy storage of complex, hierarchical data.
- Elasticsearch: When it comes to full-text search and analytics, Elasticsearch is hard to beat. I've used it to build powerful search functionality for large-scale document repositories.
- Docker and Kubernetes: These containerization and orchestration tools have made deploying and scaling data pipelines much easier. They've been crucial in building cloud-native data solutions.
- AWS/GCP/Azure: Cloud platforms have become essential in modern data engineering. Each has its strengths, and I've worked extensively with all three, using services like AWS S3, Google BigQuery, and Azure Data Factory.
ETL vs. ELT vs Data Pipelines
These terms often cause confusion, so let me break them down:
Partner with Us for Success
Experience seamless collaboration and exceptional results.
ETL (Extract, Transform, Load): This is the traditional approach where data is transformed before it's loaded into the target system.
- Pros: Good for complex transformations, especially when the target system has limited processing power
- Cons: Can be slower, as data is transformed before loading
ELT (Extract, Load, Transform): A more modern approach where raw data is loaded first, then transformed as needed.
- Pros: Faster initial loading, more flexible as raw data is preserved
- Cons: Requires a powerful target system to handle transformations
Data Pipelines: This is a broader term that can include both ETL and ELT processes. It represents the entire flow of data from source to destination.
I've found that the choice between these approaches often depends on the specific use case. For a data warehouse project I worked on, we used an ELT approach because we needed the flexibility to transform data in different ways for various use cases. On the other hand, for a project involving sensitive data, we used ETL to ensure data was cleaned and anonymized before it entered our system.
Data Storage Solutions
Data storage is a critical component of any data engineering project. Here are some solutions I've worked with:
- Data Warehouses: Tools like Snowflake, Amazon Redshift, and Google BigQuery have revolutionized how we store and query large volumes of structured data. I've used Snowflake extensively for its ability to separate storage and compute, allowing for more cost-effective scaling.
- Data Lakes: For storing vast amounts of raw, unstructured data, I've often turned to data lake solutions. Amazon S3 is a popular choice, but I've also worked with Azure Data Lake Storage and Google Cloud Storage.
- NoSQL Databases: When dealing with unstructured or semi-structured data, NoSQL databases like MongoDB, Cassandra, or DynamoDB have been invaluable. I once used Cassandra to build a system that could handle millions of writes per second for a large IoT project.
- Time-Series Databases: For projects involving time-stamped data, specialized databases like InfluxDB or TimescaleDB have proven very effective. I used InfluxDB for a project monitoring real-time sensor data from industrial equipment.
- Graph Databases: When working with highly interconnected data, graph databases like Neo4j can be incredibly powerful. I've used Neo4j to model complex relationships in social network data.
The choice of storage solution often depends on the nature of the data, query patterns, and scalability requirements. I always advocate for choosing the right tool for the job rather than trying to force-fit a solution.
Fun Fact- The largest known data pipeline, operated by CERN's Large Hadron Collider, processes about 1 petabyte of data per second during experiments - that's equivalent to 210,000 DVDs of data!
Programming Languages
I've found proficiency in multiple programming languages to be crucial. Here are the languages I use most frequently:
- Python: This is my go-to language for data engineering tasks. Its rich ecosystem of libraries (pandas, numpy, scikit-learn) makes it incredibly versatile. I use it for everything from data preprocessing to building machine learning pipelines.
- SQL: Despite the rise of NoSQL databases, SQL remains essential for working with relational databases. I use it daily for querying, data manipulation, and even complex analytics.
- Scala: When working with Spark, Scala is often my language of choice due to its performance benefits and strong typing. It's particularly useful for building robust, scalable data processing applications.
- Java: Many big data technologies are written in Java, and I've found it useful for building high-performance, enterprise-grade data applications. I once used Java to build a custom ETL tool for a client with very specific performance requirements.
- R: While more commonly used by data scientists, I've found R useful for certain statistical operations and data visualization tasks.
- Bash: For automating workflows and writing quick scripts, Bash is invaluable. I use it frequently for data pipeline orchestration and system administration tasks.
The key is to choose the right language for the task at hand. While Python is my primary language, I often switch to Scala for performance-critical Spark jobs, or R for complex statistical analyses.
Frequently Asked Questions?
What's the difference between a data engineer and a data scientist?
Data engineers build and maintain data infrastructure, while data scientists analyze data to derive insights and build predictive models.
Do I need a computer science degree to become a data engineer?
While helpful, it's not mandatory. Many successful data engineers come from diverse backgrounds and learn through practical experience and self-study.
What programming languages should I learn for data engineering?
Start with Python and SQL. Then, consider learning Scala or Java, especially if you'll be working with big data technologies like Spark.


Ajay Patel
Hi, I am an AI engineer with 3.5 years of experience passionate about building intelligent systems that solve real-world problems through cutting-edge technology and innovative solutions.




