

When evaluating machine learning models or detection systems, two key metrics consistently pop up: recall and precision. While these terms might sound intimidating at first, they're actually quite simple concepts that help us understand how well our systems perform.
Think about a system that detects cats in photos. How often does it correctly identify cats? How many real cats does it miss? These questions lead us to precision and recall – two fundamental measures that help us evaluate accuracy from different angles. Whether you're building spam filters, disease detection systems, or simple image classifiers, understanding these metrics is crucial.
In this guide, we'll break down precision and recall into bite-sized pieces, using simple examples and real-world analogies. By the end, you'll not only understand what these terms mean but also know exactly when and why to use each metric. Let's dive in!
KEY BUILDING BLOCKS
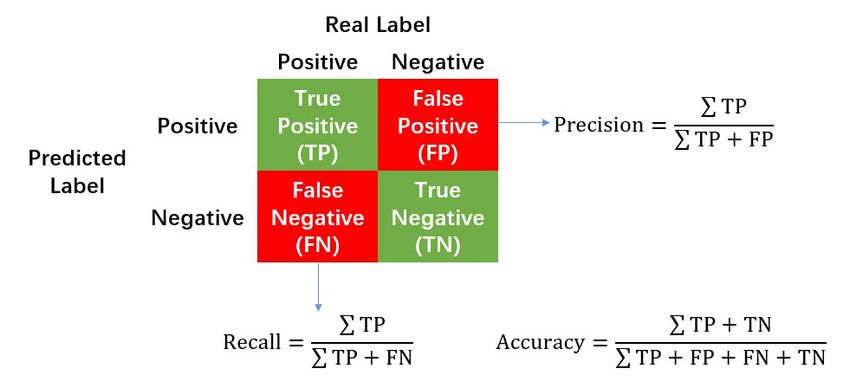
Before we jump into recall and precision, let’s first understand four key building blocks:
True Positive, True Negative, False Positive, and False Negative
Imagine you're working on a model to identify cats in pictures. For every picture, your model can either be right or wrong. Here's how we classify those outcomes:
- True Positive (TP):
- Your model says, "This is a cat."
- The picture actually shows a cat.
- 🎉 Yay! Your model is correct!
- True Negative (TN):
- Your model says, "This is NOT a cat."
- The picture indeed shows no cat.
- 🎉 Another win for your model!
- False Positive (FP):
- Your model says, "This is a cat."
- But the picture shows something else (a dog, a pillow, or even a pizza 🍕).
- 😕 Oops! Your model made a mistake.
- False Negative (FN):
- Your model says, "This is NOT a cat."
- But the picture actually shows a cat.
- 😿 Oh no! It missed the cat.
Now that we understand these four terms, let’s move on to recall and precision, which are metrics built on them.
What is PRECISION?
Let's break down precision - one of the key metrics that tells us how accurate our model's positive predictions are:
Precision answers a simple question: "When our model says 'Yes' (like identifying a cat), how often is it correct?" It's all about the accuracy of positive predictions.
Precision Formula

In Simpler Terms
- Precision focuses on being accurate with predictions.
- If your model is high in precision, it rarely calls a dog or pillow a cat.
Partner with Us for Success
Experience seamless collaboration and exceptional results.
Precision Example
- Your model identified 10 pictures as cats.
- Among them, 8 were cats, and 2 were not.
- Precision = 8 / (8 + 2) = 0.8 or 80%.
High precision is great when false positives are costly, like in spam detection (you don’t want important emails marked as spam!).
What is RECALL?
Think of recall as your model's ability to find all the hidden treasures. Here's how it works:
Recall answers: "Out of all the actual cats in existence, how many did we successfully find?" It's about catching everything that matters, even if you make a few mistakes along the way.
- Here’s the formula:

Think of it as: Found Cats / Total Real Cats
In simpler terms:
- Recall focuses on not missing any real cats.
- If your model is high in recall, it catches almost every cat, even if it occasionally mistakes a pillow for a cat.
Recall Example
Imagine there are 12 cat photos in your collection:
- Your model finds 9 cats successfully (True Positives)
- But misses 3 cats completely (False Negatives)
- Recall = 9/12 = 75% (found 75% of all cats)
When is Recall Critical?
High recall becomes crucial when missing something is dangerous:
- Disease Detection: Can't afford to miss any cancer cases
- Security Systems: Must catch all potential threats
- Safety Inspections: Need to find every possible defect
COMPARISON
The Balance: Why Not Maximize Both?
You might be thinking: "Let’s make both recall and precision 100%!"It’s not that simple.
- Maximizing recall can lead to more false positives.
- Example: Label every picture as a cat. You’ll find all the cats, but your precision will plummet.
- Maximizing precision can lead to more false negatives.
Partner with Us for Success
Experience seamless collaboration and exceptional results.
Example: Only label pictures as cats if you’re 100% sure. You’ll avoid mistakes but miss many actual cats.
This trade-off is where metrics like F1 Score (a harmonic mean of precision and recall) come into play, but let’s keep that for another day!
Visualizing The Concept
Here’s a fun analogy:
Imagine you’re a detective trying to catch shoplifters in a mall.
- True Positive (TP): You catch someone stealing.
- True Negative (TN): You don’t accuse innocent shoppers.
- False Positive (FP): You wrongly accuse someone holding a chocolate bar from home.
- False Negative (FN): You miss a thief sneaking out with unpaid sneakers.
If you arrest everyone leaving the store, your recall is 100%, but your precision is terrible. If you only arrest those who look super suspicious, your precision is great, but recall is poor.
WRAPPING UP
Precision and recall might sound technical at first, but they’re just fancy ways of asking:
- How accurate am I when I say something is true? (Precision)
- How good am I at finding all the true cases? (Recall)
With these building blocks, you’re now ready to evaluate models with confidence. Whether it's detecting cats, diagnosing diseases, or finding ads in newspapers, precision and recall are your best friends in understanding how well your model performs.
Happy learning! 🐾
Frequently Asked Questions?
1. What's the difference between precision and recall?
Precision measures how accurate your positive predictions are, while recall measures how well you find all positive cases in your dataset.
2. When should I prioritize precision over recall?
Prioritize precision when false positives are costly, like in spam detection where you don't want important emails marked as spam.
3. Why can't we achieve 100% in both precision and recall?
There's typically a trade-off: increasing one often decreases the other. Maximizing recall may lead to more false positives, while maximizing precision might miss true cases.


Sharmila Ananthasayanam
I'm an AIML Engineer passionate about creating AI-driven solutions for complex problems. I focus on deep learning, model optimization, and Agentic Systems to build real-world applications.




