

Large language models or LLMs are a type of Artificial intelligence that can mimic human intelligence. It applies neural network techniques with lots of parameters to process and understand human languages. It can perform several tasks such as text generation, summarization, audio transcription, chatbots, image generation etc.
The field of artificial intelligence (AI) has witnessed tremendous progress in recent years with the development of Large language models. To keep terms clear, distinguish them from Artificial general intelligence, which targets broad, human-level capability beyond task-focused systems. However one of the important drawbacks of these models is reliance on their internal knowledge base and limitations of their context length.
Traditional language models generate responses based on the pre-learned patterns and information during their training phase. So these models were limited with the data they trained on, often leading to responses that lacked accuracy and specific knowledge. Context length limitation is a significant challenge when working with traditional LLMs.
It restricts their ability to process and understand long-range dependencies and contextual information in text. This limitation leads to poor performance on long documents and multi-document inputs, as the model is forced to truncate or split the text, resulting in a loss of important contextual information. Techniques like chunking strategies in rag are often used alongside Retrieval-Augmented Generation to preserve important context and improve accuracy. To address these limitations researchers have proposed a new paradigm called Retrieval-Augmented Generation (RAG) which utilizes the external knowledge sources to enhance their text generation capabilities.
RAG represents the combination of traditional language models with an innovative approach. It integrates information retrieval directly into the generation process. For instance, a PDF chatbot can use RAG to provide accurate answers to user queries by retrieving relevant information from a database of PDF documents. Similarly, a customer support chatbot can utilize RAG to generate personalized responses to customer inquiries by accessing a vast knowledge base of product information and customer feedback.
WHAT IS RAG (Retrieval-Augmented Generation)?
Retrieval-augmented generation (RAG) is a technique that enhances the accuracy and reliability of generative AI models by integrating information from external sources. The core concept involves using a language model to generate text while simultaneously retrieving relevant data from external knowledge bases, enriching the output. This approach minimizes the need for continuous retraining on new data.
RAG offers several benefits over traditional language models. Unlike models that rely solely on their internal knowledge, RAG can access a vast array of external resources, enabling it to produce more accurate and context-aware responses. While conventional LLMs become static after training, RAG can dynamically incorporate new information, reducing the risk of providing outdated or incorrect answers.
Additionally, RAG excels at handling rare or unconventional topics by retrieving pertinent information from external sources. Its capacity to leverage external knowledge and adapt to new tasks makes RAG a more versatile and powerful solution than traditional language models.
CORE COMPONENTS OF RAG
1. Knowledge Base
At the heart of RAG lies the Knowledge Base, a vast repository of data that serves as the foundation for the entire system. This database contains a massive amount of documents, articles or other sources of information which are used to provide necessary information for generating responses.
The Knowledge Base is responsible for storing and organizing vast amounts of information, making it easily accessible for the retrieval system to query and retrieve the relevant information. This component is crucial in RAG, enabling it to provide more accurate and informative responses.
2. Retrieval System
The Retrieval System is the component responsible for searching the Knowledge Base for specific information and retrieving relevant information for the query or prompt. It uses advanced techniques and algorithms to identify the most relevant document or context that matches the input query.
The Retrieval System is designed to be highly efficient, able to sift through a vast amount of information or data in a matter of milliseconds. This enables RAG to generate more accurate responses, making it an ideal solution for applications where speed and accuracy are paramount.
3. Language Model
The Language model is responsible for generating human-like responses based on the information retrieved from the Retrieval system. LLMs use advanced neural network architectures such as transformers to analyze the input and generate relevant responses.
This component is the key to RAG’s ability to generate responses, making it an ideal solution for applications such as chatbots and virtual assistants.
4. Integration Layer
The Integration Layer is responsible for integrating the Knowledge Base, Retrieval System and Language Models. It is responsible for managing the flow of information between different components.
It ensures whether the Knowledge Base provides the necessary context or information, the Retrieval System retrieves relevant information and Language Models generate accurate responses. This layer also ensures that all the components are working together in the right manner, enabling the RAG to provide more accurate responses.
RAG WORKFLOW: A STEP-BY-STEP BREAKDOWN
When the query is made, the RAG system retrieves the relevant information from the knowledge base and then the retrieved information is used by the Language Models to generate the most accurate responses.
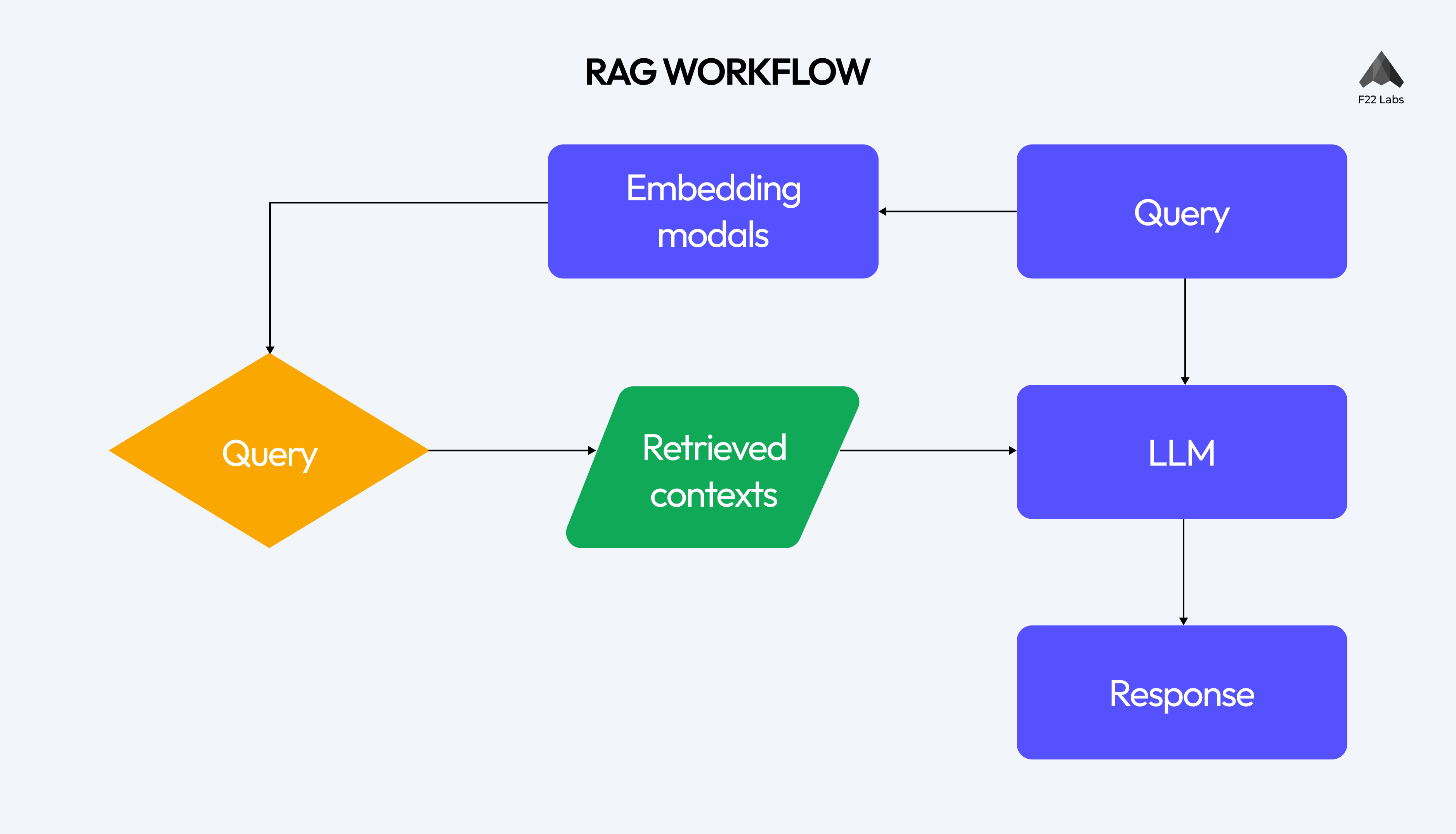
1. Query Processing
The RAG workflow begins with query processing. It processes and analyzes input queries. It could be a question, input or prompt that the language model responds to.

Walk away with actionable insights on AI adoption.
Limited seats available!
2. Embedding Model
The query is then passed to an Embedding model. The embedding model converts the query into vectors, which is a numerical representation that can be understood and processed by the system.
The input query is represented as a vector which captures its semantic meaning and importance. The various embedding techniques are Word2vec, SVD, BERT etc. Each technique has its own strengths and weaknesses and the choice of the technique depends on the specific application.
3. Vector Database Retrieval
The workflow of RAG then proceeds with the Vector Database Retrieval, where the input query is used to search for the relevant information from the vector database. The system retrieves the most relevant context based on how closely their vectors match the query vectors.
Various types of vector databases such as Qdrant, Chroma, Faiss, pinecone, Redis etc are used to store and retrieve vectors. Similarity search algorithms such as cosine similarity and dot product are used to identify the most relevant vectors in the database. This algorithm enables RAG to generate more accurate responses.
4. Context Selection and Ranking
The retrieved information is ranked and selected based on its importance and relevance. The information is scored based on its relevance to the input query. This involves techniques such as TF-IDF, semantic similarity and BM25.
The retrieved information is selected based on its relevance and coverage of different aspects of the input query. This involves techniques such as clustering, diversity-based ranking etc.
5. LLM response Generation
The LLM takes both the input query and retrieved-context to generate the relevant responses. Prompt engineering is the art of crafting clear instructions to the LLM. Prompt engineering also plays an important role in generating responses. The response is generated to balance the retrieved information and the model’s knowledge.
Suggested reads- 13 Text-to-Speech (TTS) Solutions
6. Final response synthesis
The final step in the RAG workflow is final response synthesis where the generated response is refined to ensure coherence and fluency. The response is also fact-checked and verified to ensure consistency and accuracy.
APPLICATIONS OF RAG (Retrieval-Augmented Generation)
A. Question-Answering Systems
By leveraging RAG, question-answering systems can provide more accurate responses to the query. RAG’s question-answering capabilities can be applied in various domains including
- Education
- Customer support
- Research
B. Content Generation
RAG's ability to generate human-like responses makes it an attractive solution for content generation. Want to see it in actual implementation? Check out this AI POC where we built an intelligent payslip document chat system using RAG for automated processing and response generation.
C. Conversational AI
Chatbots equipped with RAG can retrieve support documents, and product information to generate responses to user queries. It can be used in fields like customer service, healthcare and finance. In many of these scenarios, Small language models are increasingly being adopted alongside RAG to deliver faster, task-specific responses without the heavy compute needs of larger systems.
- Understand user content
- Provide personalized responses
- Virtual Assistants
D. Research and analysis tool
The RAG system helps researchers find answers to scientific questions by leveraging the vast amount of research papers and academic papers.
- Extract Insights
- Analyze the data
- Identify patterns
POTENTIAL AREAS FOR IMPROVEMENT in RAG
However, like other technologies, RAG is also not perfect and has areas of improvement.
A. Enhancing Retrieval Accuracy
One of the primary areas of improvement in RAG is enhancing retrieval accuracy. While RAG has made significant strides in retrieving relevant information, there is still some room for improvement. Some potential ways to improve retrieval accuracy include
- Improving indexing and retrieval algorithms
- By using more advanced embedding techniques
- Incorporating additional contexts
B. Reducing Latency
Optimizing the model architecture of RAG can reduce latency by reducing the number of computations required. Using more efficient hardware like GPUs and TPUs can reduce the latency by minimizing the speed of computations. Caching and Pre-computations are also important to reduce latency.
Walk away with actionable insights on AI adoption.
Limited seats available!
C. Handling ambiguity and uncertainty
Some potential ways to improve RAGs' ability to handle ambiguity and uncertainty include
- Using probabilistic models
- Using Ensemble Methods
D. Multilingual and Multi-Modal RAG Systems
- Using Multilingual embeddings
- Incorporating additional modalities
- Using transfer learning
E. Ethical considerations and Bias mitigations
- Using fairness metrics
- Incorporating Diversity and Inclusion
- Providing Transparency and Explainability
FUTURE DIRECTIONS FOR RAG
1. Integration with Other AI Technologies
One of the most promising future directions for RAG is its integration with other AI technologies. By combining RAG with other AI technologies, researchers can create more versatile systems that can overcome more complex tasks. Some potential areas of integration include:
- Computer vision
- Speech recognition
- Intelligent virtual assistants
- Content generations
2. Self-updating Knowledge Bases
Traditional RAG models rely on pre-trained knowledge bases that can become outdated over time. Self-updating knowledge bases can enable RAG models to learn and adapt to new information and updates in real time, without requiring manual intervention.
3. Personalized RAG Systems
Personalized RAG systems are another promising direction for the technology. Traditional RAG models are often designed to generate text for the general audience without considering individual preferences and needs. Personalized RAG systems enable the creation of systems that adapt to individual user preferences, interests, and language styles.
CONCLUSION
As we conclude our journey through the world of Retrieval-Augmented Generation (RAG), it’s clear that this technology has the potential to revolutionize the field of artificial intelligence.
Recap of RAG’s Importance
RAG has emerged as a game-changer in the field of AI and Natural Language Processing (NLP). By combining the strengths of retrieval and generation models, RAG has demonstrated unparalleled capabilities in generating human-like text. The importance of RAG can be summarized as follows:
- Improved Text Generation
- Enhanced Knowledge Retrieval
- Increased Efficiency
- Flexibility and Adaptability
Future of AI with RAG Technology
As RAG continues to evolve and improve, we can expect to see significant improvements in areas such as human-like intelligence, Conversational AI, content creation and also personalized experiences. While RAG may also have implications for future work, it’s essential to recognize the potential benefits and challenges that this technology presents. As we move forward, it’s crucial to invest in education and training programs that prepare workers for the changing job market and ensure that the benefits of RAG technology are shared by all.
Frequently Asked Questions?
1. What is Retrieval-Augmented Generation (RAG)?
RAG is an AI technique that enhances language models by combining them with external knowledge retrieval. It improves accuracy and context-awareness in generated responses by accessing and incorporating information from vast external databases.
2. How does RAG differ from traditional language models?
Unlike traditional models limited to pre-trained knowledge, RAG can access external information in real time. This allows it to provide more up-to-date, accurate, and contextually relevant responses, especially for rare or specialized topics.
3. What are the main components of a RAG system?
A RAG system typically consists of four main components: a Knowledge Base for storing information, a Retrieval System for finding relevant data, a Language Model for generating responses, and an Integration Layer for coordinating these components.

Kiruthika
I'm an AI/ML engineer passionate about developing cutting-edge solutions. I specialize in machine learning techniques to solve complex problems and drive innovation through data-driven insights.
Walk away with actionable insights on AI adoption.
Limited seats available!


